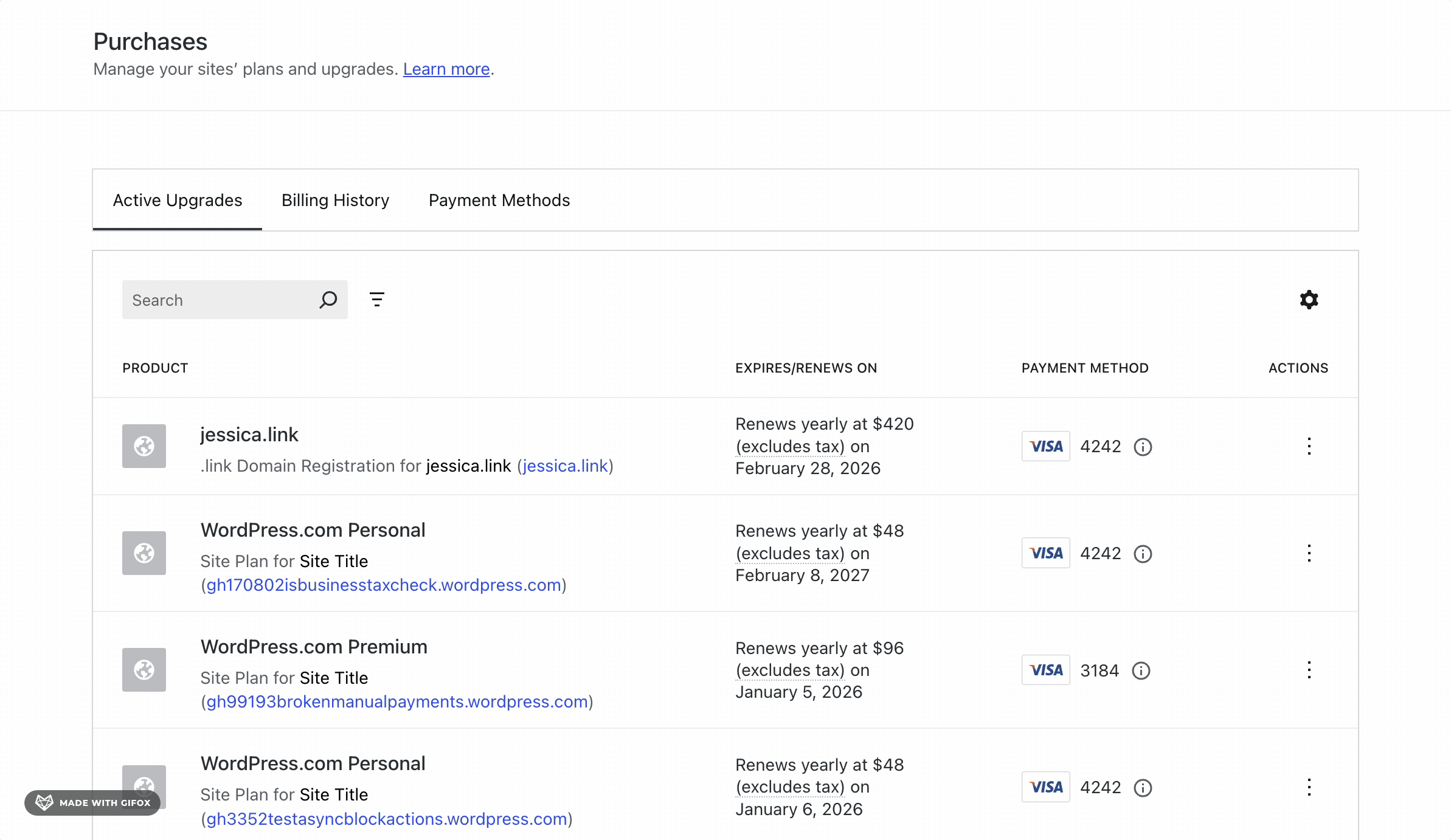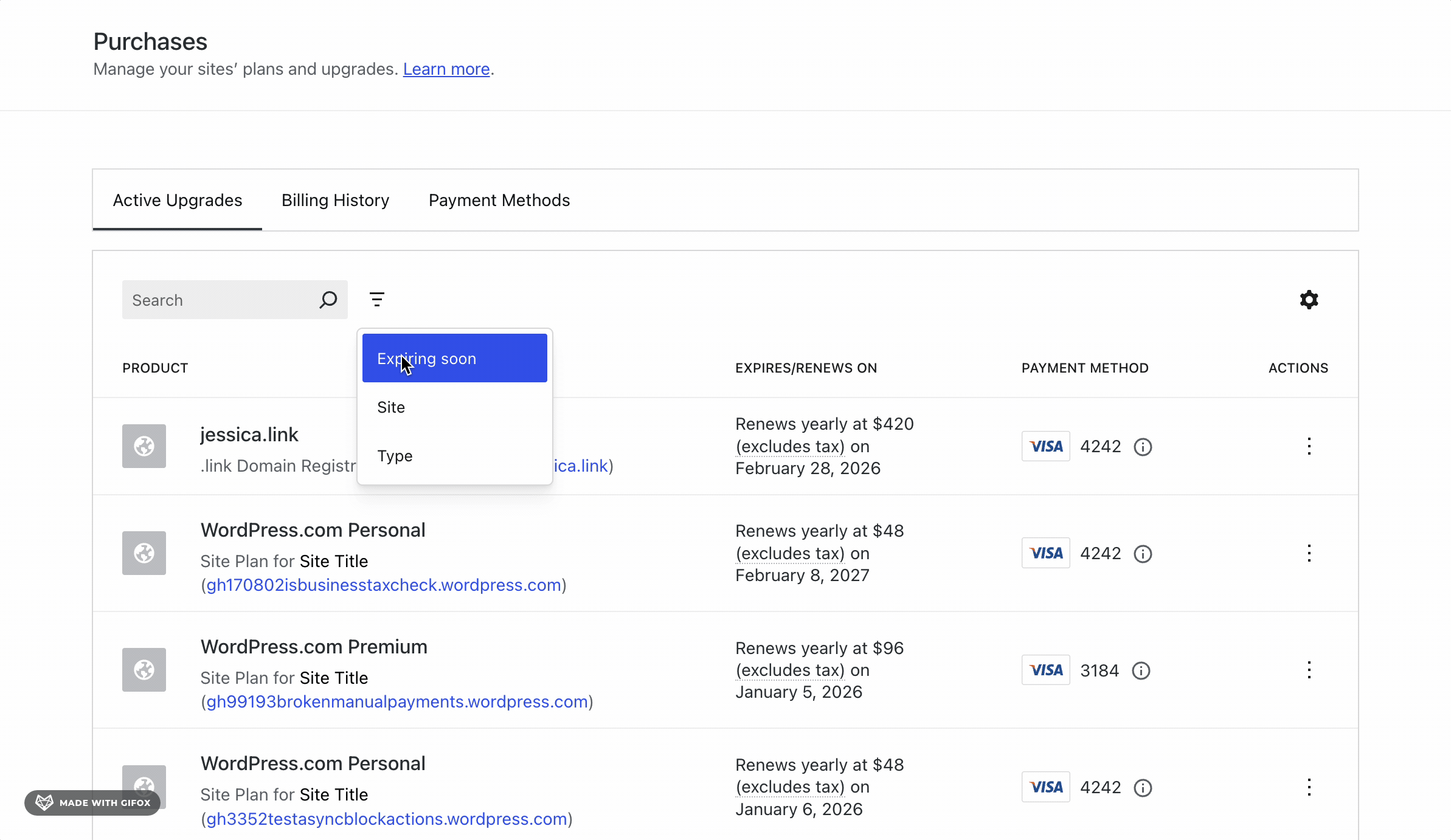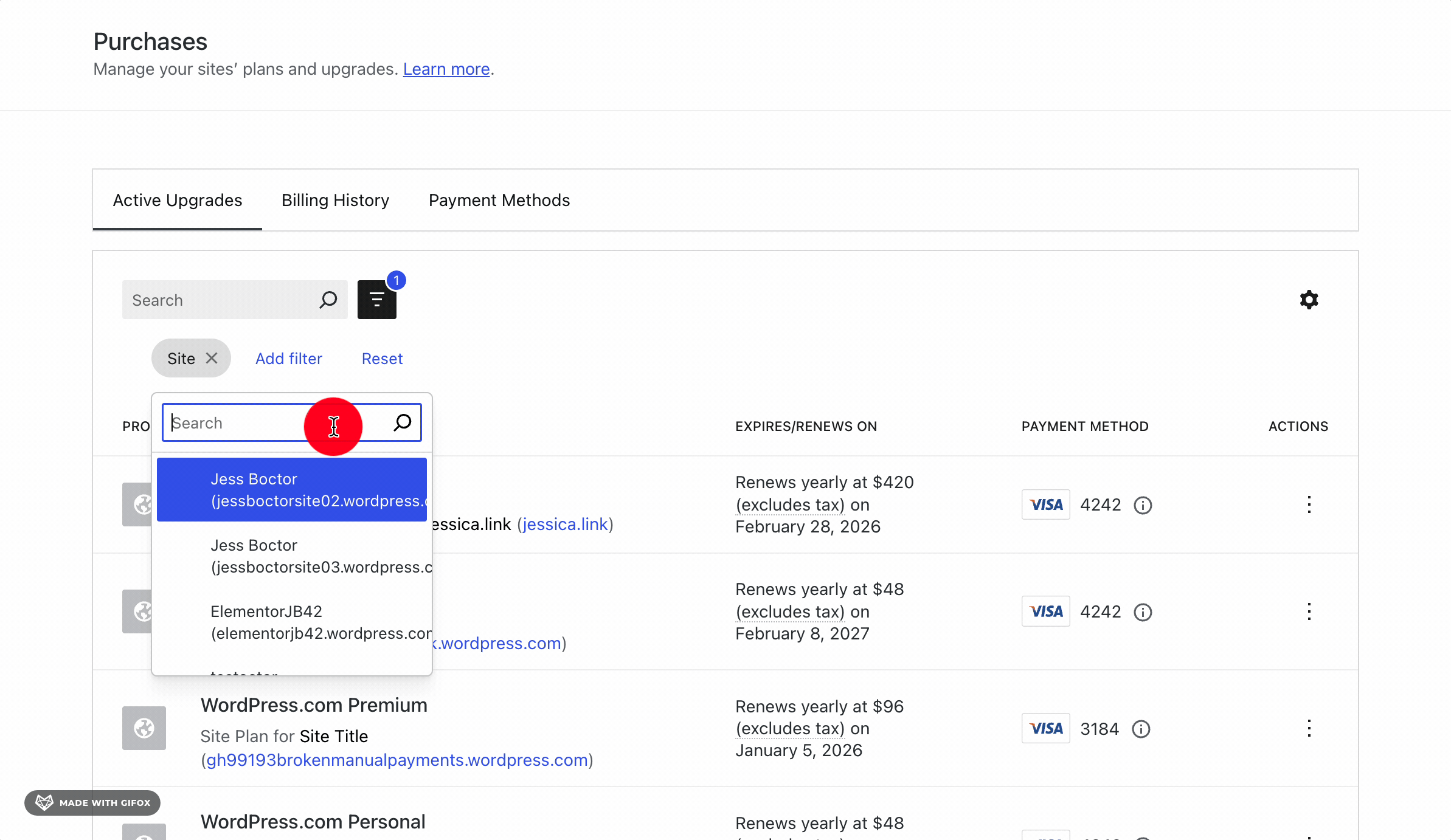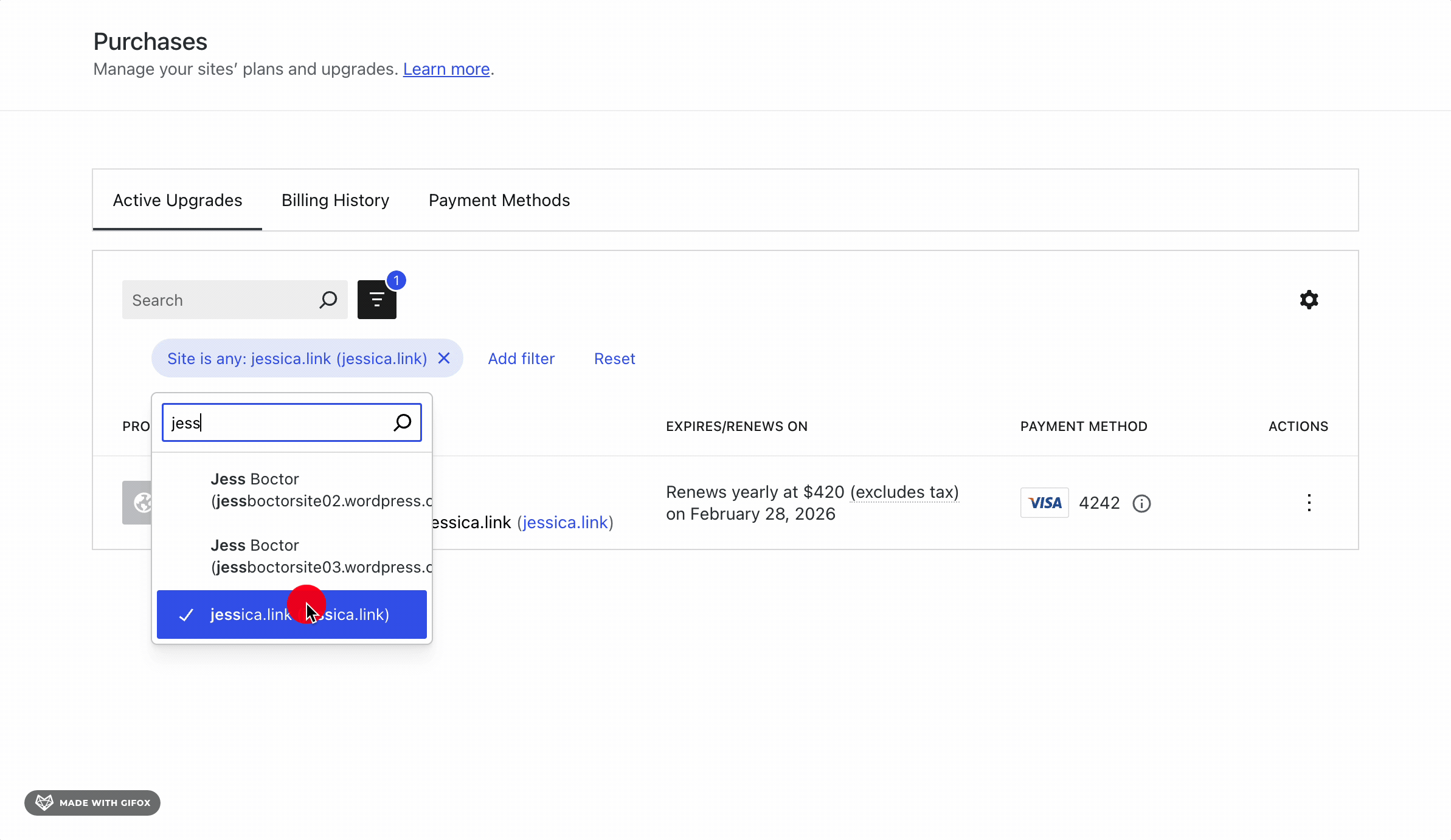
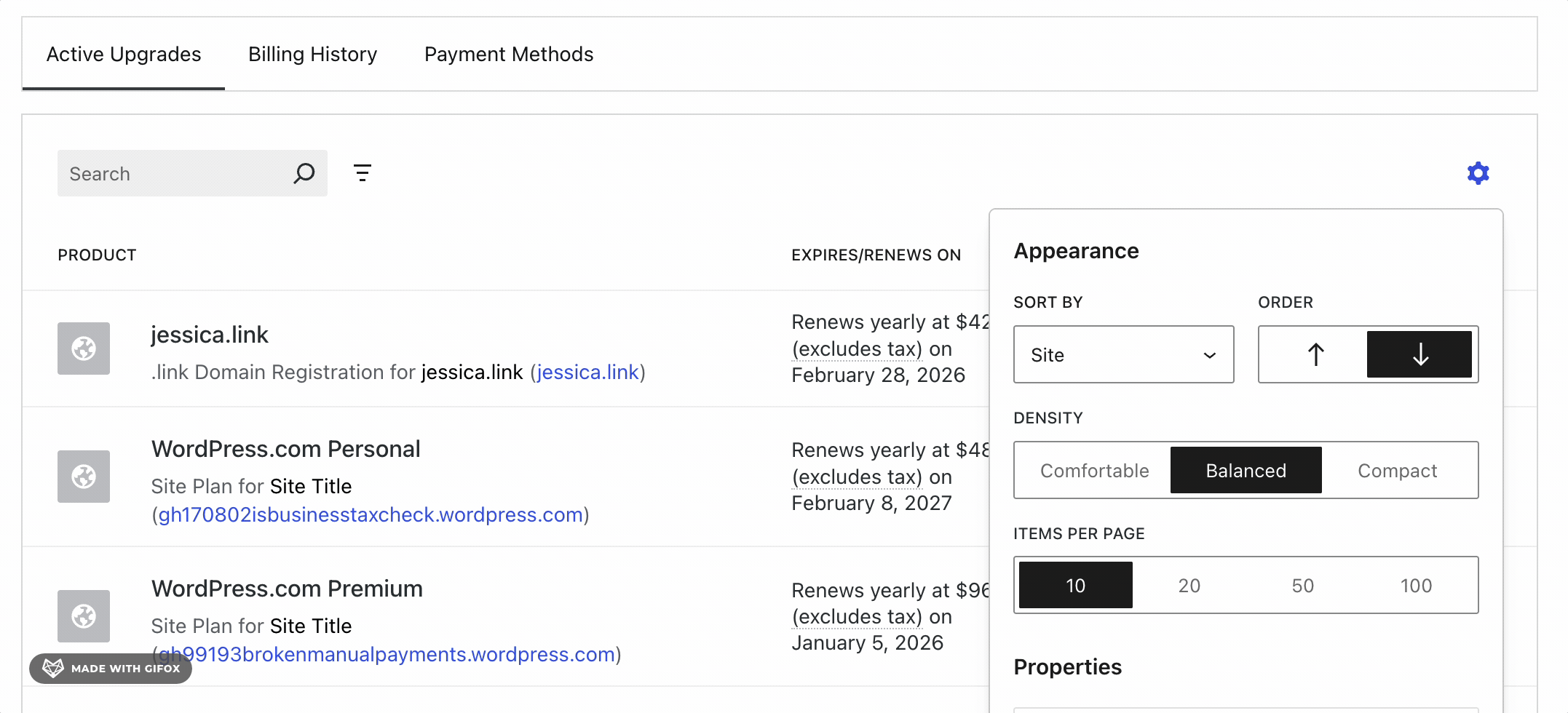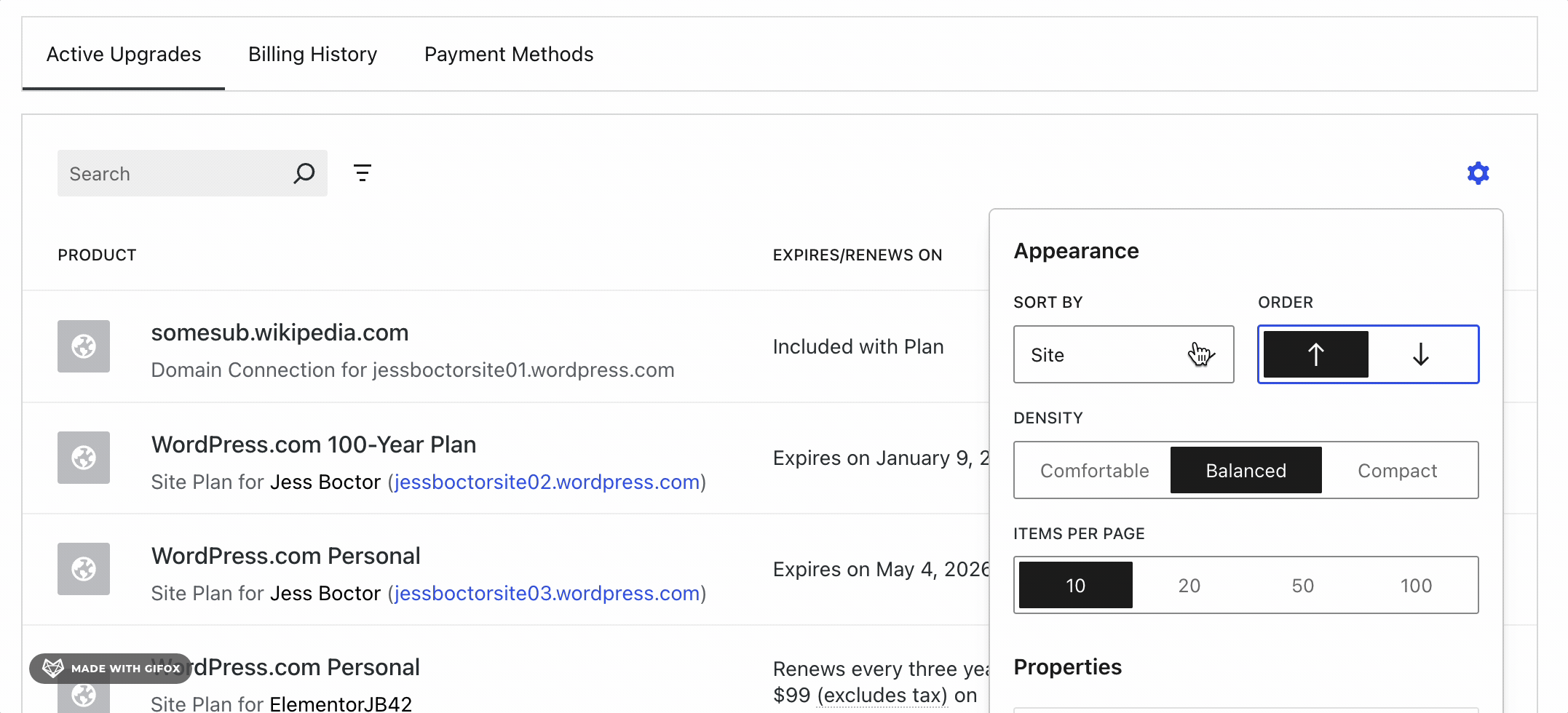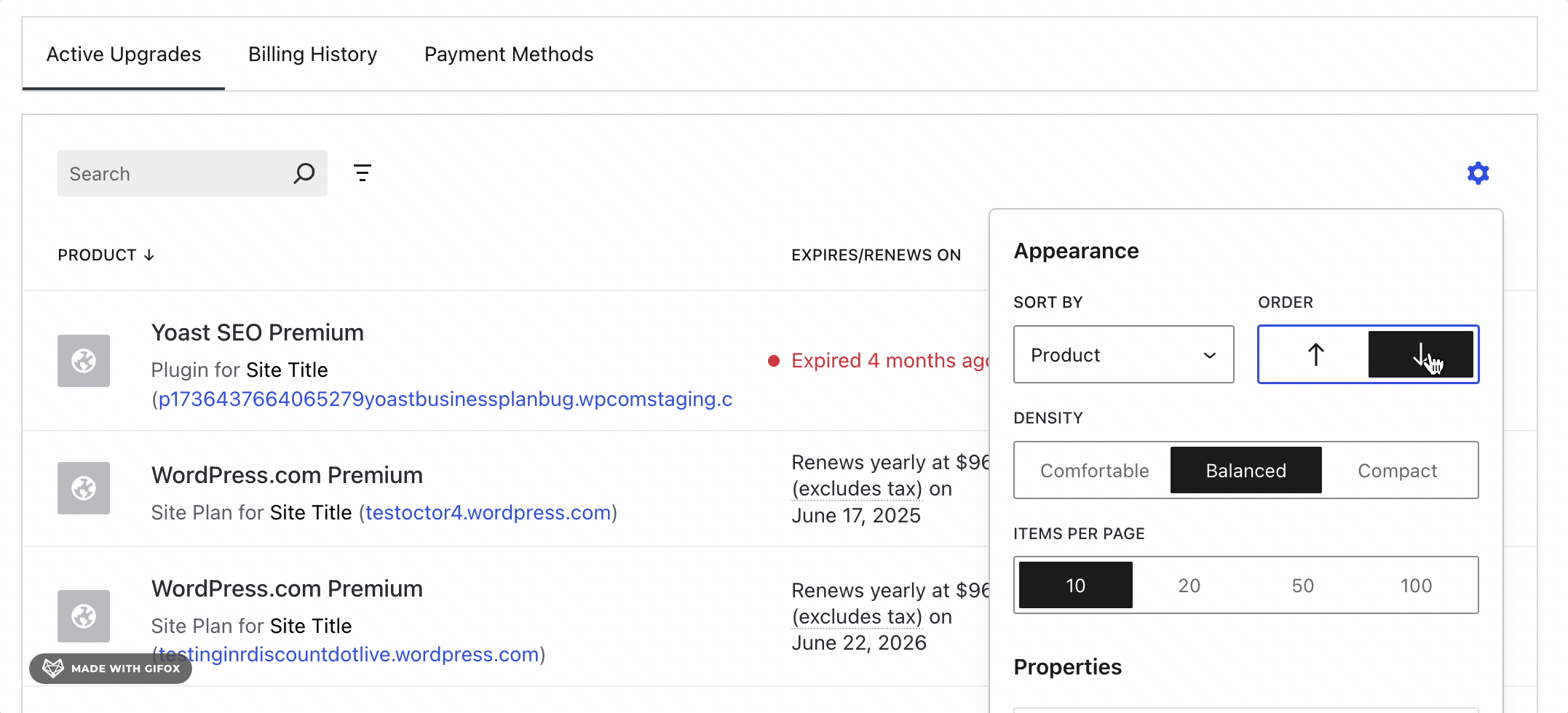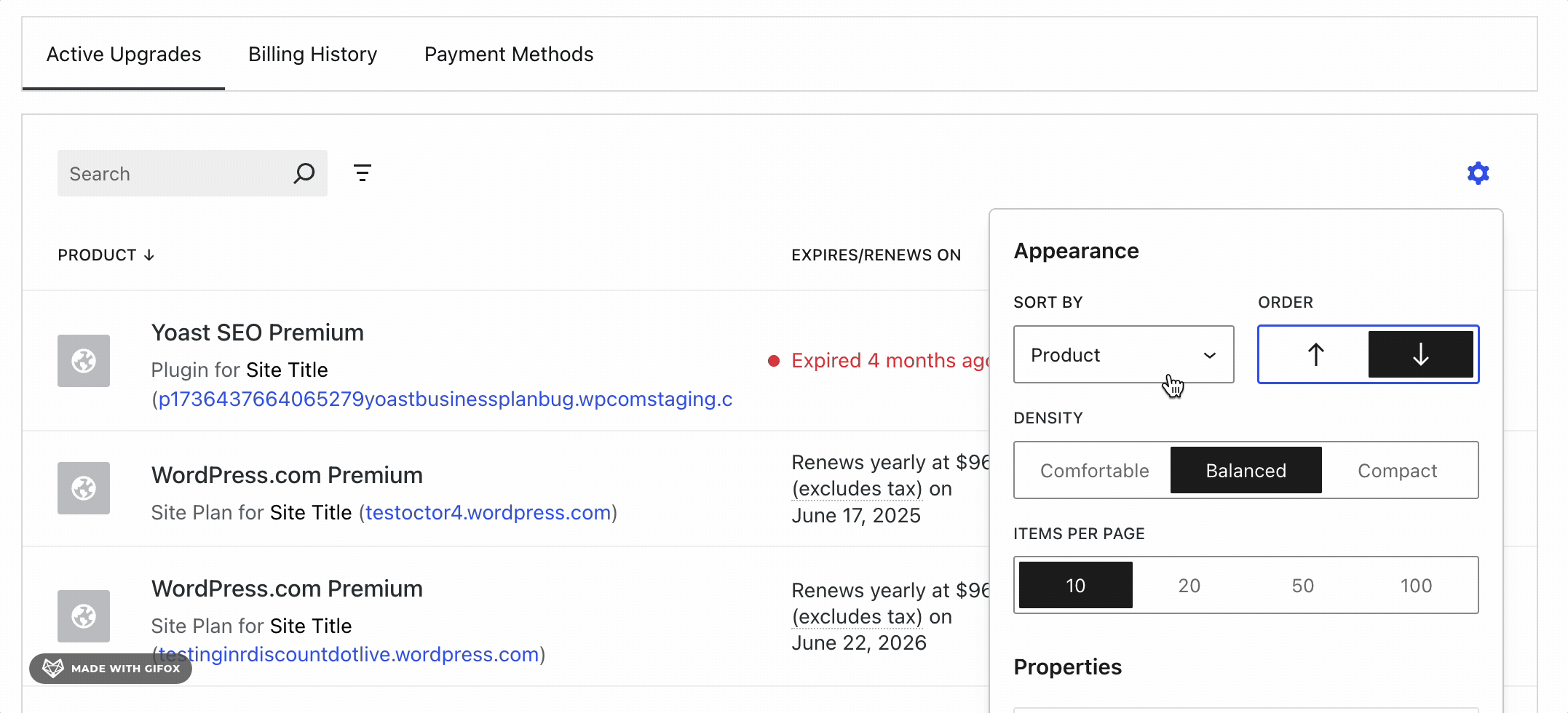
AI assisted coding like Claude or Lovable make it easy for anyone to create a web app. This type of enablement means that projects can go from ideas to launch really quickly and for, well, anyone.
But what happens when you get your first users? Figuring out how to support them can take a while.
I have more than 10 years of experience in supporting customers to help them figure out how to use SaaS products, or engineers in how to extend them.
Here’s some tips for anyone who is trying to learn support on the fly:
Tip #1: Take A Breath
In support, everything feels urgent. Very few people write to support and say, “I’m having trouble, but get back to me whenever you can!”. Rather, messages are, “Hey! It’s broken! My work is blocked! Fix it! Fix it now!”
It is easy to let their panic generate panic in you. Taking a deep breath, reading through their message multiple times, and having a defined support process will help to support users better. I was once given the advice, “Go slow to go fast”. By slowing down and paying attention, you’ll get a better sense of the issue and make fewer mistakes. Taking the time to really understand the where the user is stuck will fix their problem faster than assuming.
Tip #2: Respond In A Timely Manner
No one likes to feel ignored or dismissed. Responding to a user message within 24 hours, or one business day at the most, will let the user know you received their issue.
Don’t fall into the trap of thinking that an issue has to be resolved before responding to a user. If the issue can be resolved under an hour, then it is worth it to simply fix the thing and send a message afterwards. However, if resolving the issue will take more than an hour, it is better to respond to the user to let them know you received their message, any ideas you have about the cause of the problem, and that you are working on the fix. Once the fix is done, follow up with them to let them know.
Always execute follow-ups if you promise one. Don’t break the user’s trust by promising an update in 24 hours and then not sending it. Even if the update is “I’m still working on it”.
Tip #3: Get More Info
It seems like human nature to share problems rather than describe them. Think of when you taste something and it isn’t quite right. What’s the first thing you do? Shove the spoon in the face of the person next to you, demanding they taste it too. You don’t tell them it is too salty, or too spicy, or too…something. You just share that something is off.
Often, user’s do the same thing. They write an email and let support know that something is wrong, but they may not think to describe what the problem really is, or how they got there. It may help to create a standard set of questions if it is unclear what the issue is from the first message.
Some examples:
- What browser are you using?
- What type of computer or device are you using?
- What happened before you got here?
- Are there any error messages?
- Can you send a screenshot?
- Did this work before?
Tip #4: Clarify Expectations
What a user expects to happen is valuable information. Once you understand what the user expects, you can clarify if something is actually broken or if the user expects things work to differently than the app was designed.
Expectations provide actionable feedback to either fix the issue or to consider an enhancement. Remember, fixing everything immediately may not be the right decision. For example, if a fix requires a complete refactor of the code but only has a small number of users who are affected, it may not be worth it. Especially if there is a work around users can be directed to. On the other hand, if a fix is relatively simple, its almost always a good idea to implement it.
Tip #5: Replicate The Problem
If the user reports something is broken, confirm that you can replicate the issue. Use a test account (or even better, a testing environment) to follow the actions the user took and see if the same result can be consistently generated. By testing in multiple scenarios, the scope of the bug or issue can be narrowed down.
Tip #6: Keep Notes On Every Interaction
When support requests come in, it is easy to get overwhelmed. Notes will help prevent this. Rather than having to go back and re-read every interaction with a user, notes will act as guide posts for what has been done and what needs to be done next.
Here is a format that I use:
User: User Name
Email: user@userdomain.com
Account/Website/Identifying Information: xxxx-xxxx-xxxx
Issue: Customer got stuck trying to create a new widget
Done: Provided instructions on how to create the widget. Provided link to documentation.
Next: Nothing at the moment. All set.
User: User Name
Email: user@userdomain.com
Account/Website/Identifying Information: xxxx-xxxx-xxxx
Issue: Customer is seeing an error message when logging in.
Done: Checked their login information and account. Was able to replicate the issue. Let the customer know I would investigate.
Next: Investigate the issue and get back to customer in 24-hours with update.
Tip #7: Track Everything
If you receive feedback from a user about something being broken, or a feature request, you should keep note of it. This way, if more users contact you about the same (or similar enough) issues, you have data to impact your next steps.
When something new launches, it is easy to let the urgency and excitement make it feel like every bug needs to be fixed or feature request implemented. However, that’s an easy way to overcomplicate things or dilute the original value of the app. The app isn’t meant to make everyone happy. It is meant to provide a service. Keep your focus on the original purpose and filter out noise as needed. Listening to users is really important. Being mobbed by them is a distraction.
Tip #8: Improve Documentation
If users keep submitting the same question over and over again, then it may not be an issue with the app but it might be with the documentation. Public documentation which is up-to-date and easy to understand is a key way to support users who are learning how to use your product.
Tip #9: Define processes
As you start figuring out how to help users, start writing standard operating procedures and processes for commonly requested issues. For example, when and how do you give a customer a refund? If there is a bug that needs help from engineering, how do you escalate that? If an account needs to be transferred to a new user, do you allow that? Deciding these types of issues and writing down the process will give a more consistent support experience to your users.
This can also extend to creating canned responses which can be sent to common questions. This speeds up the process of responding to messages.
Tip #10: Did I miss anything?
If you feel there was something I missed, or have a pro-support tip, then please feel free to submit it in the comments!